If you are setting up a new table in Postgres, the first line is probably going to look like this:
CREATE TABLE my_table (
id INTEGER PRIMARY KEY,
...
);
You’re going to have an id of type INTEGER, and you’re setting it as the PRIMARY KEY.
If this is you, congrats, you can stop reading right here. However, if this is you:
CREATE TABLE my_table (
id INTEGER,
...,
UNIQUE (id)
);
Then, read on. Your tables might not be working as you intended.
The importance of primary keys
TL;DR: Always use primary keys for your id columns
Primary keys are really important in Postgres. They bring many benefits to the table (pun intended!).
First and foremost, primary keys act as a unique identifier for any row in a table. This is almost always the main reason developers add them. This uniqueness trait means no two rows can have the same primary key value, ensuring that each row is distinctly identifiable.
Primary keys enforce non-nullability, meaning every row must have a valid primary key value. This combination of uniqueness and non-nullability guarantees data integrity and prevents any ambiguity or duplication in the table.
There are several other cool features you get when you add PRIMARY KEY to your table, including:
- Automatic indexing. Postgres automatically creates an index on the primary key column, which speeds up queries that search or join based on the primary key. This index helps Postgres quickly locate the desired rows without scanning the entire table, improving query performance.
- Logical replication: Primary keys play a vital role in logical replication setups. Postgres uses the primary key to accurately identify and synchronize rows across the source and target tables when data needs to be replicated between databases. The primary key is the anchor point for tracking changes and ensuring data consistency during replication.
- Referential integrity. Primary keys are commonly used as the target of foreign key constraints in related tables (FK in the schema example above). By establishing these relationships, you can maintain referential integrity and ensure that data remains consistent and properly connected across multiple tables in your database. Foreign keys help enforce the integrity of the relationships between tables.
- Query optimization. Postgres query optimizer can leverage primary keys to generate more efficient query plans. When you have a primary key defined, the optimizer can make informed decisions about index usage, join order, and other optimization strategies, leading to faster query execution.
Unique constraints
TL;DR: Avoid using UNIQUE as a substitute for PRIMARY KEY
Using primary keys is the widely accepted convention and best practice in relational database design. But sometimes, developers skip the primary key to use unique constraints instead.
Unique constraints do exactly as their names suggest–they make a column unique. This means no two rows can have the same value for the constrained column. But unique constraints have some key differences compared to primary keys that may complicate things in production.
For example…
Unique constraints allow for null values
Let’s illustrate why this is problematic. Let’s go back to the e-commerce store example, where each user must have a unique id. Imagine that we decide to define this id as a unique constraint vs a primary key:
CREATE TABLE users (
id INTEGER,
username VARCHAR(50),
email VARCHAR(100),
UNIQUE (id)
);
Let’s say users are added like this:
INSERT INTO users (id, username, email)
VALUES
(1, 'john_doe', 'john@example.com'),
(2, 'jane_smith', 'jane@example.com'),
(3, 'mike_johnson', 'mike@example.com');
But now, imagine that due to a mistake or a bug in the user registration code, a new user is added without an id:
INSERT INTO users (username, email)
VALUES
('alice_brown', 'alice@example.com');
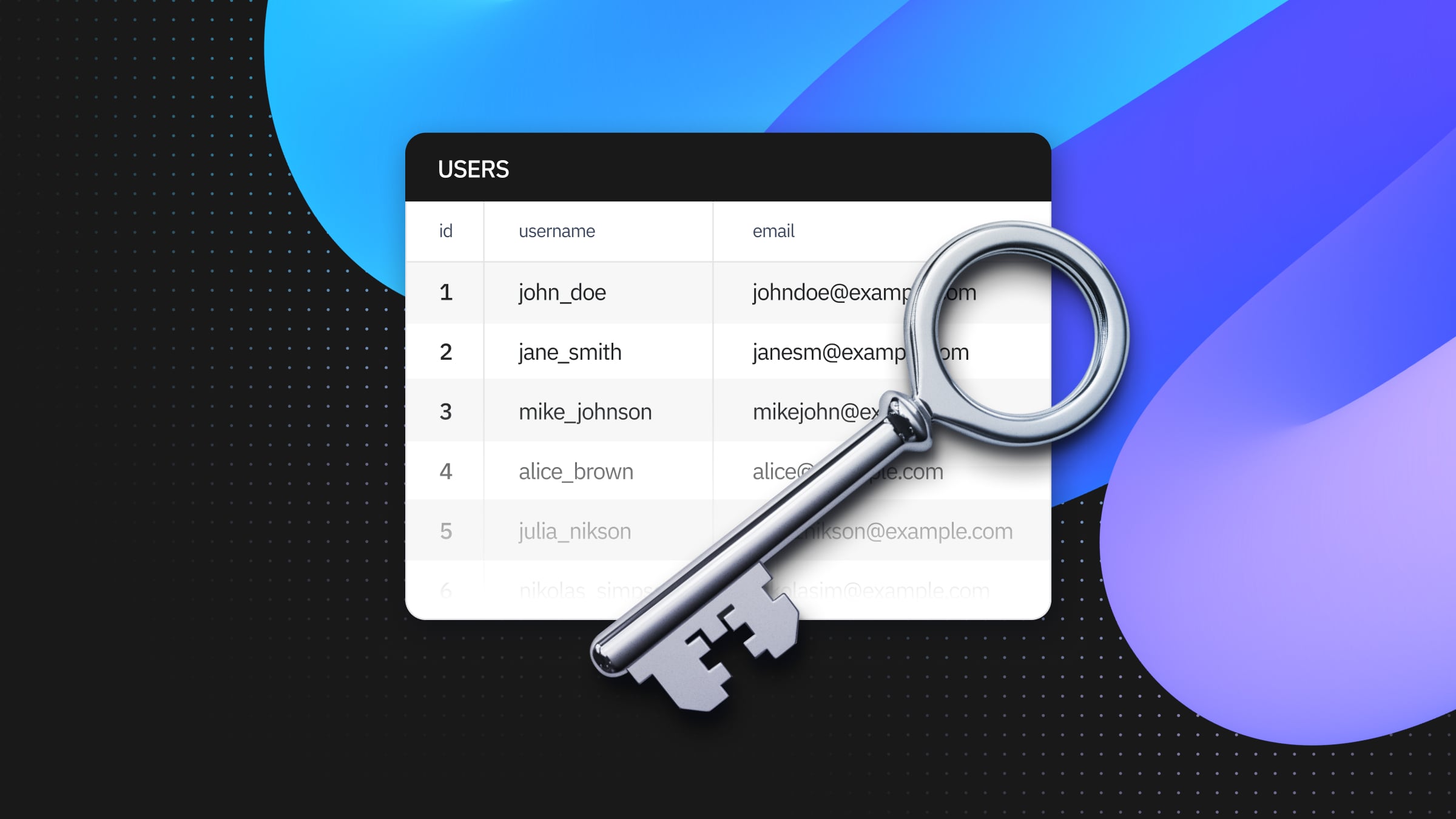
The system doesn’t throw an error because, according to Postgres, NULL values are considered unique. Now your table looks like this:
id | username | email
----+--------------+-------------------
1 | john_doe | john@example.com
2 | jane_smith | jane@example.com
3 | mike_johnson | mike@example.com
| alice_brown | alice@example.com
This can cause you multiple problems in the long run:
- If multiple rows are allowed to have NULL values in a unique column, it can lead to duplicate entries that violate business rules.
- Unique constraints with NULL values might degrade the performance of index lookups.
- Queries that rely on the unique constraint for filtering or sorting may return ambiguous results.
- IReports and analytics relying on unique constraints might produce incorrect results, e.g. aggregating data based on user IDs.
Ways around this?
- By adding the
NOT NULLconstraint to the column along with theUNIQUEconstraint, you can ensure that the column does not accept any null values. This combination ofUNIQUEandNOT NULLconstraints mimics the behavior of a primary key, preventing both duplicate and null values in the column. - Instead of manually specifying the values for the unique identifier column, you can use the
SERIALdata type in Postgres.SERIALautomatically generates a unique sequential integer value for each new row inserted into the table. By usingSERIAL, you can avoid manually assigning unique values and ensure that each row has a non-null, auto-incrementing identifier.
Or, you can just use the primary key and forget about all of this.
Unique constraints make logical replication more difficult
Using unique instead of primary key can also be problematic when using logical replication. Postgres uses the primary key as the default replica identity, which means it relies on the primary key values to match and replicate changes accurately. If you choose to use a UNIQUE constraint, the automatic benefits of PRIMARY KEY disappear when it comes to logical replication.
Unlike primary keys, unique constraints do not automatically serve as the replica identity. When a table lacks a primary key and only has a unique constraint, Postgres does not have a default way to uniquely identify rows for replication purposes. You must manually specify a replica identity using the REPLICA IDENTITY command, adding an extra step to your replication setup. If we have our users table from above, we can ALTER that to add an identity:
ALTER TABLE users REPLICA IDENTITY USING INDEX users_id_key;
When using unique constraints for replication, you must ensure that the constraint covers all the necessary columns to uniquely identify a row. This will probably require creating a composite unique constraint across multiple columns:
CREATE UNIQUE INDEX users_composite_key ON users (username, email);
This will be more complex and harder to maintain than using a single primary key.
Remember to use primary keys
There are plenty of places within tables where UNIQUE can be helpful in any inherently unique column, such as emails, usernames, or SKUs. But just set a primary key as the id. If you have a secondary key you want to add–a UUID, a natural key, or a composite key–that’s great. But get used to typing id SERIAL PRIMARY KEY, and you’ll have a much easier time with Postgres.